
Google Chrome внедряет функцию, позволяющую пользователям копировать текст из отсканированных PDF-файлов. Это долгожданная возможность.
Одна из самых неприятных вещей при открытии PDF в Chrome — это всегда вероятность того, что исходный документ был отсканирован, а не создан в цифровом виде. В этом случае текст не был бы виден средству просмотра PDF в Chrome, а значит, его нельзя было бы скопировать как текст. Это также означало, что поиск по странице в Chrome был бесполезен.
В недавнем обновлении Google сделал средство просмотра PDF немного более надежным. Теперь Chrome может распознавать текст в отсканированных документах. Это означает, что текст можно копировать, выделять и искать с помощью «Ctrl + F».
Эта функция была первоначально представлена в Chrome Beta, но, похоже, стала доступна большему количеству пользователей. Новый инструмент служит ресурсом для пользователей, позволяя находить текст в документах, даже если они были импортированы оптически. Цифровой файл сохраняет этот признак, благодаря которому Chrome всегда мог распознавать текст, но отсканированные файлы не имели этого текстового признака, делая их нечитаемыми для средства просмотра PDF в Chrome.
Эта функция работает точно так же, как и для обычного PDF-файла при копировании текста в Chrome. Выделение текста позволит вам его скопировать, а поиск по странице покажет результаты для введенной фразы. Кажется, что в средстве просмотра нет никакой разницы между одним документом и другим.
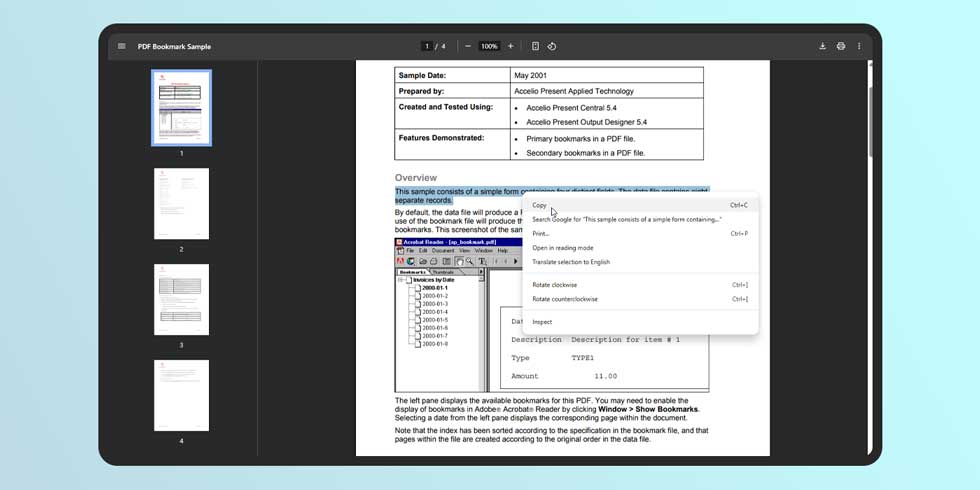
Было лишь вопросом времени, когда Chrome представит эту функцию, учитывая, что Google Lens стал такой важной частью веб-браузера. Распознавание текста уже было функцией, но эта реализация кажется гораздо более интегрированной.