Большие языковые модели (LLM), такие как Google Bard, обучаются на «триллионах слов», чтобы понять, как люди говорят, и предсказывать/генерировать следующие слова в предложении, которые делают ответ хорошим. Однако эта технология на самом деле не осознает, что является фактически правильным. Учитывая новизну, некоторые – что понятно – еще не знают об этом факте. В случае с Bard, одно конкретное явление, которое произошло через дни, если не часы, после запуска раннего доступа, заключается в том, что люди приравнивают его ответы к официальным новостям и анонсам Google.
Поскольку основной механизм LLM заключается в предсказании следующего слова или последовательности слов, LLM пока не полностью способны различать точную и неточную информацию. Например, если вы попросите LLM решить математическую задачу, она предскажет ответ, основываясь на других, которые она изучила, а не на основе продвинутых рассуждений или вычислений.
С момента запуска во вторник люди спрашивали Bard о невыпущенных продуктах Google и о том, собирается ли компания делать то или иное. Некоторые из сгенерированных ответов явно оговариваются как слухи.
Однако другие ответы, сгенерированные Bard, выглядят как смелые анонсы будущих планов продуктов, например: «Да, Google планирует интегрировать Bard в Google Assistant». После объяснения того, что такое Assistant и Bard, ответ гласит, что это произойдет «в ближайшие недели». Еще более смелым является то, как он претендует на описание будущей функциональности и описывает предполагаемое мышление/обоснование Google для этого шага.
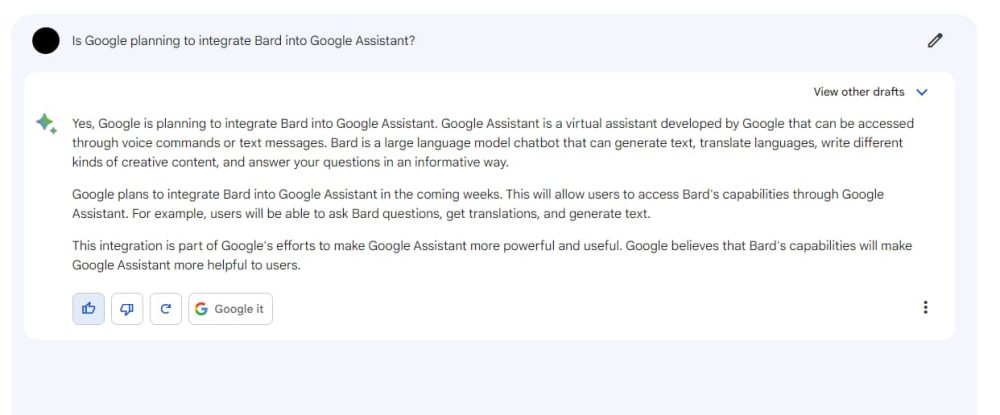
Ничего из этого неправда
Все это неправда, и, скорее всего, основано на статьях или комментариях, в которых просто говорится, что Google следует интегрировать Bard в Assistant. Компания не делала однозначного заявления, не определяла временные рамки и не анонсировала возможные функции. Bard черпает свои знания из общедоступной информации, которую вы уже можете найти, а не, например, из внутренних документов компании.
Другим особенно вопиющим примером является новостная статья о том, когда выйдет Pixel 7a, с указанием даты, полностью основанная на скриншотах чьего-то разговора с Bard. Аналогично, брать ответ от Bard и выдавать его за официальную позицию или точку зрения Google просто безответственно и граничит с дезинформацией.
С точки зрения медиаграмотности, я бы сказал, что каждый раз, когда кто-то публиковал «анонс Google», основанный на Bard, другие быстро указывали на природу LLM и их галлюцинаций. Конечно, эти разговоры велись в более ориентированных на технологии кругах. Меня беспокоит, как выглядят разговоры вне этой грамотной аудитории.
Еще более тревожно то, что происходит, когда люди просто быстро смотрят на заголовок или короткое сообщение и воспринимают эту «информацию», сгенерированную Bard, как факт, способствующий тому, что они считают происходящим/правдивым.
По мере того, как технология развертывается, люди в конечном итоге узнают о ее ограничениях. По иронии судьбы, в данном случае осведомленность о том, что LLM могут и чего не могут делать, значительно выиграла от ажиотажа вокруг предполагаемого сознания/разума, актов газлайтинга и другого странного поведения. В этом смысле я несколько надеюсь, что мы относительно быстро преодолеем этот период.
Но до тех пор: Bard не обладает никакой внутренней информацией о невыпущенных продуктах Google, их датах выпуска и других анонсах или новостях только потому, что он сделан Google.