
Google анонсировала AI Test Kitchen как способ позволить людям «узнавать о новейших технологиях ИИ, получать опыт их использования и оставлять отзывы». Впервые представленная на I/O 2022 в мае и запущенная в августе, AI Test Kitchen «Сезон 2» был представлен сегодня с акцентом на генераторы text-to-image.
Существующие три демонстрации — Imagine It, List It и Talk About It — сосредоточены на более диалоговых сценариях, основанных на LaMDA (Language Model for Dialogue Applications). Сезон 2, который выходит скоро, посвящен генерации изображений по текстовому описанию:
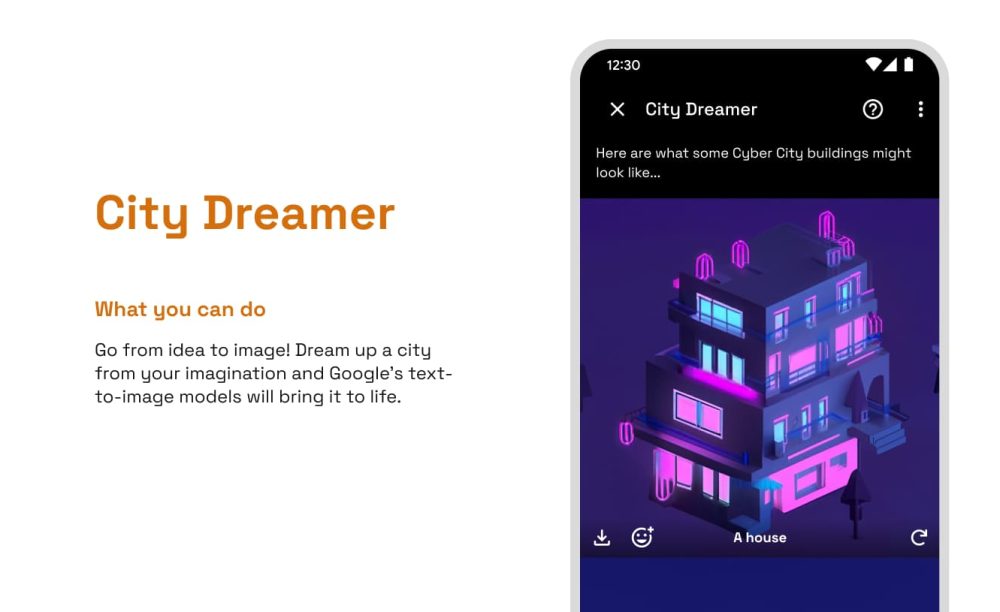
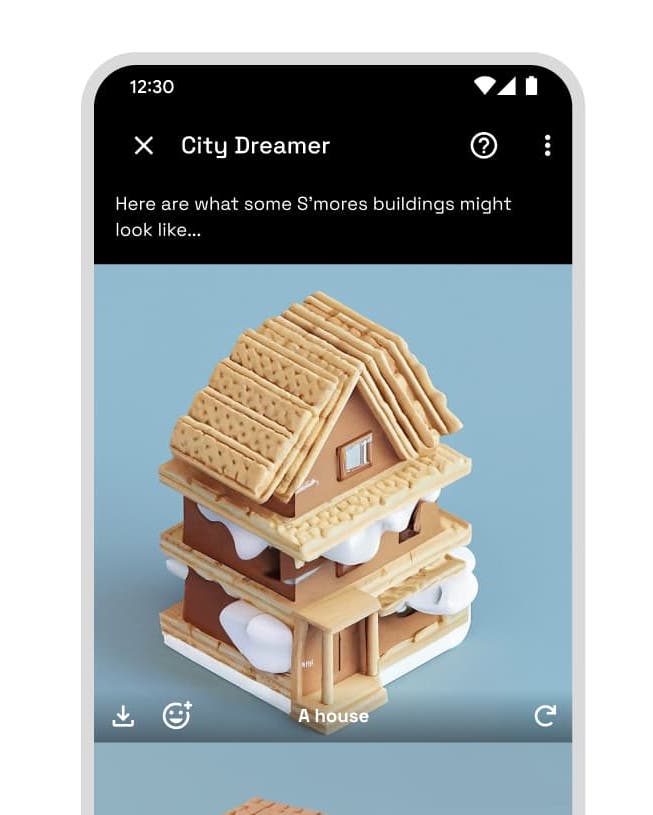
- City Dreamer: Вообразите город своей мечты, и модели Google text-to-image воплотят его в жизнь.
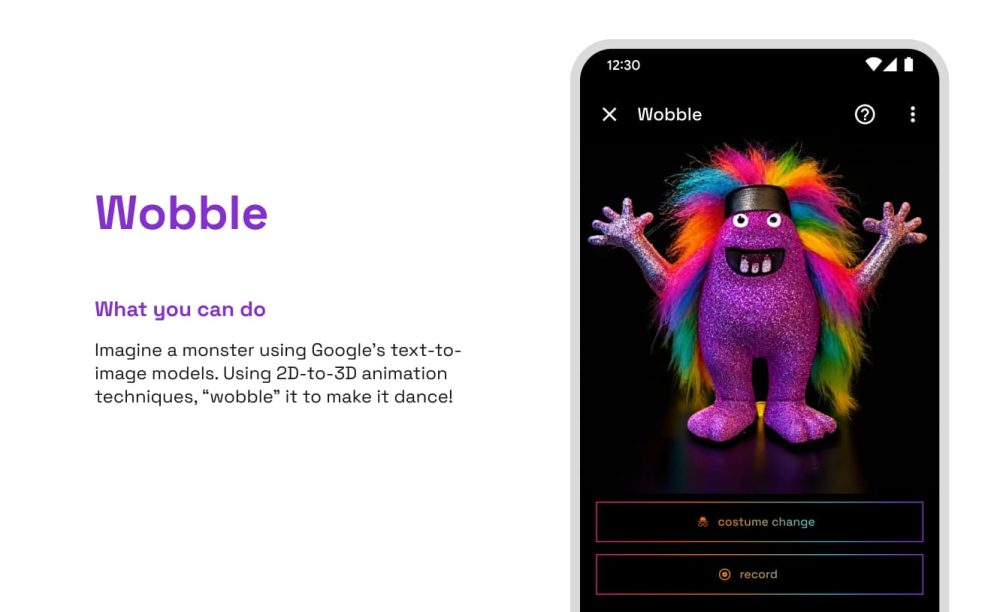
- Wobble: Представьте монстра, используя модели Google text-to-image. Используя методы 2D-to-3D анимации, «расшатайте» его, чтобы он танцевал!
AI Text Kitchen доступен на английском языке для пользователей Android и iOS в Австралии, Канаде, Кении, Новой Зеландии, Великобритании и США.
В более широком плане Google сегодня подробно рассказала о работе над моделями от text-to-image к text-to-video.
- «Imagen Video генерирует видео высокой четкости, используя базовую модель генерации видео и последовательность чередующихся пространственных и временных моделей супер-разрешения видео».
- «Phenaki — это модель для генерации видео из текста, с подсказками, которые могут меняться со временем, и видео, которые могут длиться несколько минут».
В совокупности, по словам Google, получаются работы с «супер» разрешением и «временной согласованностью». Примеры ниже были созданы Phenaki с помощью Imagen Video, увеличивающей разрешение с 128×128 до 512×512:
Что касается LaMDA, Google исследовала «пределы совместного написания» с ИИ, привлекая 13 профессиональных писателей, включая Робина Слоуна (известного по книге 24-часовой книжный магазин мистера Пенумбры, где оборудование Google для сканирования книг играет свою роль) и Кена Лю (обратите внимание на Пантеон). Вы можете прочитать короткие рассказы прямо сейчас в рамках Wordcraft Writers Workshop.
Среди других представленных сегодня работ генеративного ИИ — AudioLM и DreamFusion:
- «Так же, как языковая модель может предсказывать слова и предложения, следующие за текстовой подсказкой, AudioLM может предсказывать, какие звуки должны следовать за несколькими секундами аудиоподсказки».
- «…text-to-3D теперь реальность благодаря DreamFusion, который создает трехмерную модель, которую можно просматривать под любым углом и композировать в любой трехмерной среде».
Помимо расширенного отслеживания наводнений и лесных пожаров сегодня, Google анонсировала многолетнюю инициативу «1000 языков» по созданию модели ИИ, которая будет поддерживать 1000 наиболее распространенных языков.