
Google Discover, который, пожалуй, является ключевым способом поиска историй для чтения на Android, столкнулся с серьезной проблемой откровенного, едва замаскированного плагиата в веб-историях.
Сегодня Google Discover занимает видное место на мобильных устройствах, появляясь в приложении Google, на странице новой вкладки Chrome, на главной странице Google.com и на крайнем левом домашнем экране телефонов Pixel. Таким образом, он может служить шлюзом к контенту со всего интернета, включая новостные статьи, посты в блогах, публикации на Reddit, видео/короткие ролики на YouTube и, с недавнего времени, «веб-истории».
Впервые представленные в Google Discover в октябре 2020 года, веб-истории — это способ для веб-создателей создавать короткие, насыщенные визуальными элементами повествования в формате, похожем на «Истории» в Snapchat и Instagram. За последние два года Google значительно упростил создание собственных веб-историй, в частности, благодаря интеграции с WordPress.
Неизбежно, простота использования и заметное размещение веб-историй в Discover привели к тому, что некоторые злоумышленники стали злоупотреблять системой. В интернете в целом нередко случается, что кто-то берет работу, проделанную другими, и выдает ее за свою, хотя такие случаи обычно отлавливаются алгоритмами Google и удаляются с первых страниц результатов поиска.
Однако, судя по всему, эти меры защиты от плагиата в настоящее время не распространяются на веб-истории, которые появляются в Google Discover. В последние недели мы заметили множество вопиющих примеров веб-историй в ленте Discover, которые являются откровенными копиями статей, опубликованных такими изданиями, как 9to5Google, Android Police и CNBC. Фактически, в ходе нашего тестирования почти каждое обновление ленты Discover включало одну или несколько сплагиаченных веб-историй.
На скриншотах ниже мы видим три примера этой проблемы в действии. История на первом скриншоте, опубликованная «Insane», использует заголовок, графику и текст из нашей колонки Bandwidth. Другой пример от Insane заимствует контент у CNBC.
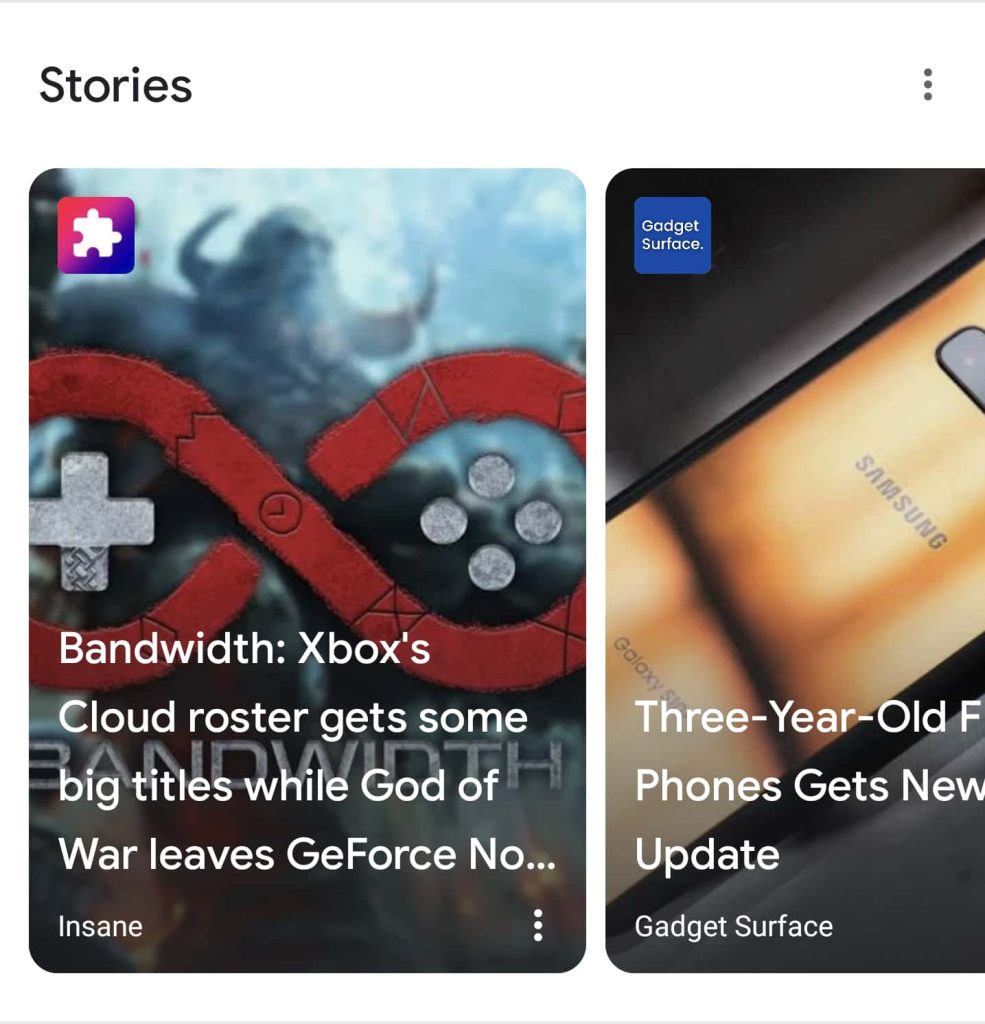
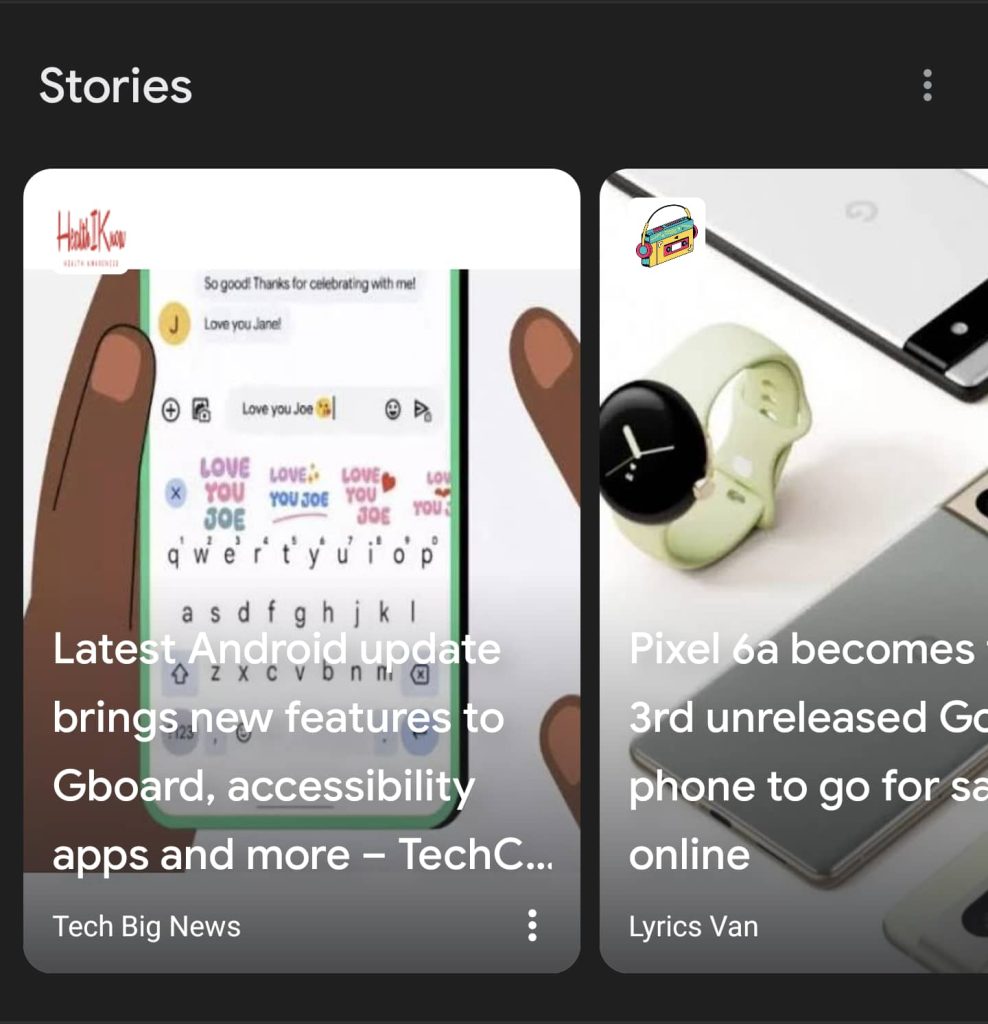
На втором скриншоте рядом расположены два примера сплагиаченных веб-историй. Первый, от «Tech Big News», использует заголовок из статьи TechCrunch и состоит исключительно из ссылок на сплагиаченные статьи. Рядом с ним веб-история от «Lyrics Van» берет заголовок статьи Android Police и совмещает его с текстом публикации от 91mobiles.
Так что же можно сделать, чтобы пресечь эту проблему? В своем заявлении Google переложил ответственность на издателей, указав на существующий в компании процесс удаления контента по юридическим основаниям. По словам компании, это основное средство правовой защиты для Поиска Google, Discover и веб-историй.
Веб-истории предназначены для отражения оригинальных работ, и мы призываем правообладателей сообщать о нарушении авторских прав. Если мы получаем уведомление о контенте, который нарушает чьи-либо авторские права, мы принимаем соответствующие меры.
— Представитель Google
Кроме того, в Google нам сослались на сложности лицензирования авторских прав и потенциальные случаи добросовестного использования, которые, по их словам, затрудняют автоматическое пресечение нарушений авторских прав. Помимо этого, нам сообщили, что система ранжирования страниц компании понижает ценность спама или плагиата в Поиске и Discover, хотя это, похоже, не мешает историям появляться в карусели веб-историй.
В сложившейся ситуации издатели несут единоличную ответственность за обнаружение и сообщение о случаях плагиата их контента. Проблема в том, что нет способа предотвратить создание нового вредоносного сайта после того, как предыдущий был удален, что заставляет веб-создателей играть в бесконечную игру «ударь крота».
Очевидно, что ответственность за эту проблему лежит на Google, поскольку именно алгоритмы компании решают, что появляется, а что нет в ленте Discover каждого человека. Веб-истории должны проходить те же проверки на откровенный плагиат, что и результаты Поиска Google. Просто смешно, что это не было встроено в формат/продукт с самого первого дня, и что Google не проявил никакого намерения решать корень проблемы.